对某个软件进行中文化时,很多次可能已经被翻译过,这些翻译记录为我们提供了宝贵的建议,翻译工具PoEdit提供TM(Translation Memory)功能,可以利用已有的翻译成果而不必从头开始。
例如在Ubuntukylin下,进入PoEdit的首选项->翻译记忆,点击“我的语言框”下面的“添加”按钮,选中zh(Chinese)
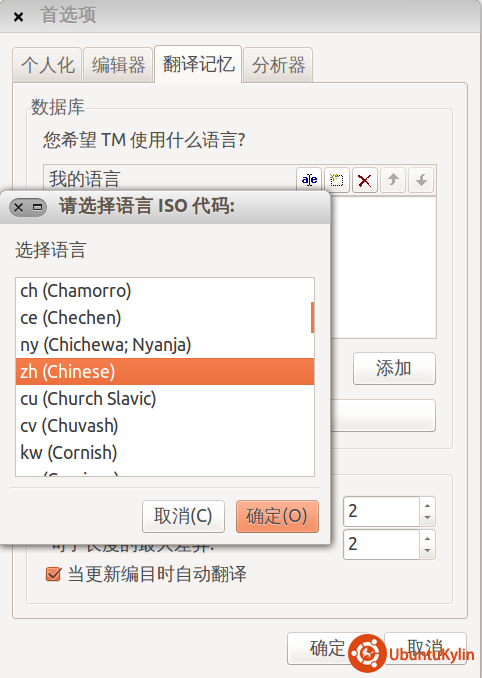
“我的语言”中就会多出一个zh的语言,选中这个语言,然后点击“生成数据库”,表示我们要生成中文的数据库。
这里还有个“配置”选项,里面的设置表示利用TM自动翻译时,待翻译条目与数据库条目之间容许的差异,如果两个条目的差异在设置的数值之内,则认为他们能够模糊匹配。“当更新编目时自动翻译”表示利用POT文件更新当前PO文件后,PoEdit利用TM进行自动翻译。
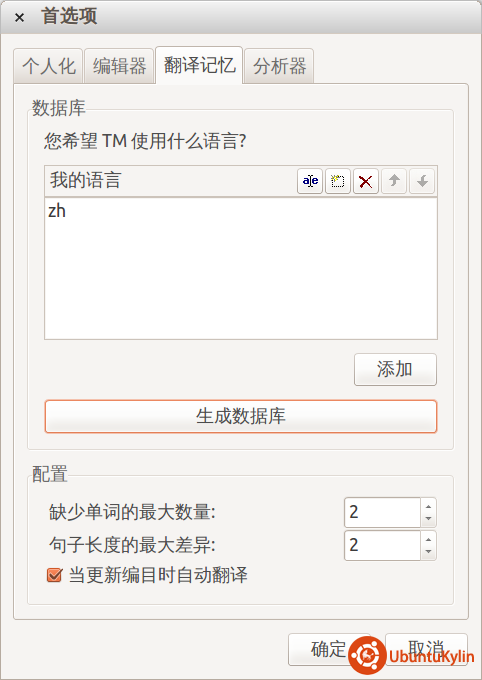
弹出的对话框要要求我们选择本地语言在系统中的位置,Ubuntu下默认的语言文件位置在“/usr/share/locale”下
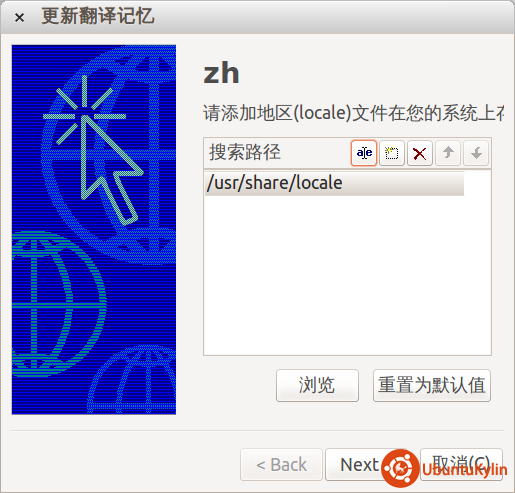
点击“Next”下一步,PoEdit会自动寻找zh类型的翻译文件(.mo文件),包括zh_CN, zh_TW, zh_HK等简繁体中文,可以通过“文件列表”后面的红叉删除文件,也可以通过“添加文件”增加其它.mo文件

然后再点“Finish”,就会导入.mo文件生成翻译记忆数据库,这个过程比较慢,需要耐心等待。
数据库生成之后,以后还可以通过这种方式更新补充数据库。
要使用翻译词库,有两种方法,一种是使用TM自动翻译,点击PoEdit的“编目”菜单,选择“使用TM自动翻译(_A)”,PoEdit会自动从翻译记忆库中提取精确匹配或模糊匹配的翻译。对于模糊匹配的翻译,可以通过点击翻译界面的“模糊”按钮或利用“CTRL+U”快捷键切换状态。第二种方法是右键点击待翻译项,弹出框中会给出自动翻译的建议,可以直接选中作为翻译。下图中有简、繁两种建议,这是因为之前生成数据库时包含了繁体中文(如zh_TW, zh_HK)的mo文件。如果不想有繁体,在生成数据库时注意排除这些文件。

PS: 可以看到PoEdit自身还有一些界面没有完整翻译,说明这个事业需要大量志愿者参与,不过还好PoEdit是给翻译人员用的,界面大家都能看懂,影响不大。
本帖参考了PoEdit的百度百科条目